一、AI产业:GPT驱动,进入工业化时代
GPT-4:面对复杂问题能力时大幅提升
 (相关资料图)
(相关资料图)
GPT-4面对复杂问题能力时大幅提升,对AP考试、GRE考试等表现优异。OpenAI在官网表示,GPT-4虽然 在大多数现实场景中的能力不如人类,但在一些专业问题和学术基准上表现已经和人类持平。根据OpenAI 在其技术文档所公布的数据,GPT-4在60%的AP考试科目中取得了5分(满分)的成绩,并较前一代GPT3.5取得了30%以上的提升。而对于国外研究生入门考试的GRE,GPT-4取得了339+4的成绩,超越95%的 应试者。
GPT-4:引入了图片的输入识别能力
多模态能力成为GPT-4加入的新亮点。GPT-4在模型能力方面最大的提升在于引入了多模态的处理能力。除 了此前ChatGPT就支持的文字外,GPT-4还可以接受图片输入,根据OpenAI在技术文档内给出的实例来看, GPT-4可以理解图中的各类含义甚至包括人类的幽默能力。不过在当前阶段,图片输入的功能暂时还没有开 放给用户使用。
技术趋势:GPT将逐步成为生成式任务的优选
尽管都是Transformer模型,Bert模型采用双向使用Mask的方法进行训练;而GPT则是采用了自回归 +prompting的方式。这两者的区别根据谷歌资深AI科学家Jeff Dean在2020年的文章回答,Bert路线在 NLU(自然语言理解)的能力以及准确度会更好,而GPT路线在NLG(自然语言生成)的表现会更突出。 通俗来说,BERT是完形填空,GPT为命题作文。
产业影响:虽然不是颠覆式创新,但探索产业化可能性增加
Chat-GPT的强势“出圈”成为了对人工智能中短期内的产业化方向一系列探索的催化剂。 从对Chat-GPT的测试结果来看,Chat-GPT 开始能在大范围、细粒度问题上给出普遍稳妥的答案,并根据上 下文形成有一定的具备逻辑性的创造性回答,在文字领域表现突出。 通过调整数据集、奖励函数调整的方式,能够依靠chatGPT的思路向其他垂直领域迈进,文字、图片、视频 等的生成同样可以值得期待,AIGC相对更为靠近。 但由于chatGTP在训练初的数据限制,不能输出超过自身“学会”的内容,而搜索引擎所用的是发散和关联, 所以不会颠覆搜索引擎。
算法模型:此前模型以堆叠参数和数据为主
小模型(2015年前)
AI擅长特定领域的分析任务,但通用型任务的完成情况很差。硬件算力不够导致重新训练成本过高;数据来源过于稀少难以提 升到更高精确度,整体表达能力与人类相差较远。
大模型(2015-2022年)
Transformer模型的出现使得文字、图像识别等领域达到了超越人类的水平,但同时也极大增加了模型的体积,只有拥有强大算 力支撑的科技巨头才有能力训练Transformer模型。
算法模型:使AI算法模型迈向新阶段
ChatGPT的成功一改往日大模型依靠堆积数据量的训练方式,RLHF(人类反馈强化学习)和Reward model(奖励 模型)是其核心训练逻辑。 ChatGPT的成功推动AI算法模型展现出更加明晰的发展脉络,使行业迈向了兼顾经济性与可使用性的新发展阶段, 展望未来,模型开放+快速优化迭代或将成为AI实现大规模应用落地的终极发展形态。
应用场景:实现UGC到AIGC的助推器
Chat-GPT的出现所带来的内容生成能力将会为当今从用户创作(UGC)到AI创作(AIGC)的转型提供关键的辅助支持。目 前我们正经历从Web2.0开始向Web3.0转型的启航阶段,在过去五年我们已经看到内容创造从专业创作(PFC)转型为了用户 创作(UGC)。而在不远的将来,AI协助内容生成(AIUGC)与AI创作(AIGC)将为我们提供更低的创作门槛以及更丰富的 创作思路。在这两个阶段中。内容生产主体从人类本身开始向人工智能迁移,主要区别体现在内容的生产效率、知识图谱的 多样性以及提供更加动态且可交互的内容上。人脑只能基于自己的知识图谱进行少数方向的信息处理,而AI能从更庞大的知识 体系中进行多个方向的处理,进而提供更多的创作思路。Gartner预计,到2025年,生成式人工智能将占所有生成数据的10%。
二、算法模型:AI产业灵魂,技术路线持续向GPT方向收敛
AI技术发展的核心主线:通用人工智能(AGI)
底层算法与模型是贯穿人工智能技术发展的核心,从上世纪50年代第一次提出人工智能概念开始,底层算法 经历了多次迭代。而贯穿多次迭代的主线是研发出真正的通用人工智能(AGI),即用一个模型解决大多数 的问题,通过这一方式才能真正做到降低人工智能的成本并取代人类。
2015年 AlphaGo:将多年积攒的研究成果展现给大众
AlphaGo 是由 DeepMind(后被谷歌收购)开发的人工智能程序,代表了从上世纪90年代开始深度学习、蒙特卡洛树搜索 等先进技术的集大成者,实现了人工智能在围棋领域的重大突破 。 2015年,AlphaGo 首次与欧洲围棋冠军樊麾对弈,并以5-0的成绩取得胜利。2016年,AlphaGo 在一场备受瞩目的比赛中 战胜了韩国围棋世界冠军李世石,向世人展示了其在围棋领域的强大实力。 AlphaGo 的成功引发了全球范围内对人工智能和深度学习的关注,展示了机器在复杂问题解决和策略制定方面的巨大潜力。
AlphaGo成功的背后:人工智能研究种类繁多且杂乱
虽然AlphaGo在围棋领域取得了巨大成功,但仍无法解决通用人工智能问题,其方法在其他领域的应用受到 局限。一人工智能研究方向众多且缺乏统一,导致学术界和产业界的资源分散,影响整体发展 。 图像检索:深度学习为主的方法;图像生成:对抗神经网络为主的方法;推荐系统:蒙特卡洛树等方法等。
后AlphaGo时代:NLP成为通用人工智能(AGI)的可能解
尽管AlphaGo及其背后的深度学习无法解决通用人工智能问题,但其给人工智能这一领域重新带来了关注度 。 在这一阶段,NLP(自然语言处理)开始展现其对通用人工智能(AGI)的潜力。语言是人类历史上最具表 述力的工具,人类的所有知识都可以通过语言进行表述,因此以语言为基础的NLP任务开始被人们寄予厚望 。研究者们开始尝试将NLP模型从特定任务的优化扩展到多任务学习,以便在各种任务上取得更好的表现。这 也反映了通用人工智能的目标,即让AI系统具备广泛的知识和技能,以应对不同领域的问题。
ChatGPT:理想的人机交互接口,更接近想象中的“人工智能”
ChatGPT以自回归模型+Zero/Few Shot Prompt(0提示或少提示)的方式,不需要在使用时对任务进行刻意区分。 模型针对任何问题都可以进行生成,缺点是面对理解类问题(分类等)精度不如以谷歌Bert为代表的微调模型。从产品逻辑上,虽然牺牲了部分精度,但Prompting无需用任务区分器区别不同的任务,是理想的人机交互接口。 面对用户不同的输入,模型可以自行判断给了用户更好的体验,这也更接近于大众理解的“通用人工智能”。
大语言模型的竞争壁垒:数据源、工程能力与资本投入
从GPT-3开始到谷歌的PALM,网络中的公开语言数据源已经在被尽可能地利用(论坛、新闻、维基百科、社 交媒体等等)。ChatGPT证明了结合人工生成数据能获得更好的效果,未来人工生成数据与算法合成数据将 占据更重要的地位。
技术端的市场动态:Meta
Meta在人工智能技术上始终是紧随微软与谷歌之后的追赶者,Meta的研究院FAIR常年在人工智能顶级刊物上发表论文位 居前列。FAIR在NLP方面有着大量研究,一个著名的项目是BERT的前身——ELMo,这是一个通过双向语言模型训练得到 的上下文相关词向量表示方法。 作为微软与谷歌的追赶者,FAIR非常积极推动开源项目的建设和资源共享。例如,FAIR开发了PyTorch,这是一个非常受 欢迎的深度学习框架,广泛应用于学术界和工业界。2023年3月Meta又开源发布了其最新的大语言模型LLaMA。
三、数据集: AI粮食和血液
“数据爆发+数据复杂度提升”是行业底层驱动力
数据结构复杂度不断提升,半结构化、非结构化数据占比不断提高。数字经济时代每分每秒都在产生大量的语音、图像、视频等非结构化数 据。不同场景、不同应用、不同来源的数据都汇聚在数据库中等待分析,数据结构本身的复杂度不断提升。此外,非结构化数据占比持续提 高,但价值仍然没有被充分发掘。根据Ovum数据,视频类数据流量占据超过77%的总流量比例。根据IDC数据,非结构化数据占整体数据 量比重高达80%以上,在排除一定比例的半结构化数据后,现阶段真正用于大数据分析支撑企业决策的只有占较小比例的结构化数据,这意 味着绝大部分非结构化数据的价值还未被充分发掘。
存储技术和云计算的发展使企业能够存储海量非结构数据,人工智能技术极大地提高对非结构数据的需求并最终赋能应用。过去由于存储技 术、资源和数据库技术的限制,非结构化的数据无法有效保存和调用。但随着存储技术和云计算的不断发展,企业可以拥有充足的、可扩展 的存储资源和存储方法。机器学习、自然语言处理、图像识别等人工智能技术也增加了对海量非结构化数据的需求。在存储非结构化数据之 后,赋能应用之前,必须经过数据库管理系统才能够对非结构化数据进行调用、处理和分析,才能让数据资产化并赋能企业发展。
大语言模型的数据用在预训练、微调两个过程中
按照当前LLM的技术范式,数据集主要应用于预训练、模型调优阶段。预训练阶段需要大规模、多类别、 高质量的训练数据,在模型调优阶段,垂类小数据集、提示词工程同样重要。
中国数据标注行业:市场保持快速增长,应用场景越来越广泛
市场规模:2022年中国数据标注市场总规模达50.8亿元,较2021年增长17.3%,CAGR(2022-2029)达22%。稳步落 地阶段的人工智能行业叠加国家产业政策支持,持续促进行业发展。同时,随着ChatGPT成为AIGC现象级应用,优化 了上游国内数据标注厂商的工作,带来更多的机会。
四、算力: AI产业的卖水者,短期最具确定性
训练成本测算—ChatGPT:预计单次训练成本约151万美元
假定预训练单次,且训练过程中没有出现错误时的成本。实际情形中,考虑到训练过程中出现工程类错误的可能性,实际 成本会高于我们计算的理想情况成本。
假设参数量为175B、训练数据500B Tokens的情况下,根据《Scaling Laws for Neural Language Models》(Jared Kaplan, Sam McCandlish, Tom Henighan等),我们在使用256个英伟达HGX A100服务器(包含2048个A100 GPU卡)的 情况下,模型FLOPs Utilization(MFU)假设为Megatron-LM的51.04%,我们推测单次训练时长约为30.7天,对应约151 万GPU小时。假设训练使用成本价约为1美元/GPU小时的情况下,耗费服务器端成本约为151万美元。
推理成本测算—ChatGPT:每2000万DAU对应成本为14.3亿美元
ChatGPT推理环节成本测算:我们假定企业会在推理环节对通信延迟、内存带宽等进行必要优化,因此假定用户访问 ChatGPT的单次成本为理论最高成本(2.7美分/次)的30%,也即0.8美分,假定目前ChatGPT目前2000万日活跃用户, 用户每天调用次数为10次,单次调用成本0.8美分,我们采用英伟达HGX服务器进行算力承载,并假定HGX A100服务器的 价格为8美元/小时,实际使用率为70%,则我们估算每天算力成本为160万美元,对应英伟达A100卡9.5万张,假定每张 A100卡售价1.5万美元,对应成本14.3亿美元,加上训练端的成本,共计约14.6亿美元。
五、应用场景:从分析型AI到生成式AI,不断逼近AGI
文本生成:聊天机器人-Character.AI
聊天机器人:Character.AI、Replika、Glow 。 GPT-3等大模型的突破性进展促进了个性化聊天机器人的发展。其中Character.AI开发了自己的 Pre-trained 模型,用户在 此基础上进行创作。技术方面,公司底层模型以包含解码器的神经语言模型为基础,类似 GPT 和 LaMDA,对话质量好 于 GPT3。具有立足生活、娱乐领域,具有深度个性化、超级智能等优点。 聊天机器人从应用场景可以分为工作与生活娱乐两个象限,在商业化层面,聊天机器人公司可以通过收取增值订阅会员、 UGC AI 角色付费订阅、凭借真正个性化的推荐布局广告业务。
文本生成:辅助写作-Jasper
辅助写作:Jasper、Microsoft、 Copy.ai、Copysmith.ai。 AI writer通过优秀的AI算法,能够帮助文字工作者在创作过程中提高效率。其中Jasper公司在2022年十月完成了一轮1.25 亿美金融资额,估值15亿美金的融资。技术方面,Jasper利用优质文案预训练精调了 Davinci 模型,根据场景填入合适参 数,提示用户填入生成所需的重要信息,以合适的结构组织好输入,发送请求给 GPT-3。同时公司也对Surfer SEO、 Outwrite进行整合,扩展公司业务质量。目前Jasper可以帮营销人员提高效率,已经在一些垂直行业开始替代对写手的需 求。伴随着技术发展,文本生成的成本下降,更多大语言模型公司将推出相应辅助写作的产品。
(本文仅供参考,不代表我们的任何投资建议。如需使用相关信息,请参阅报告原文。)
关键词:



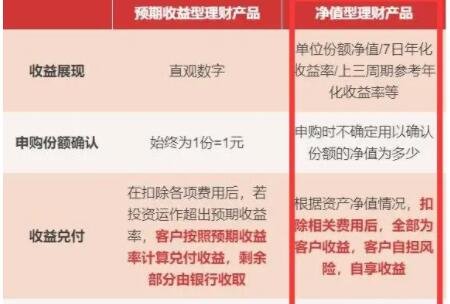

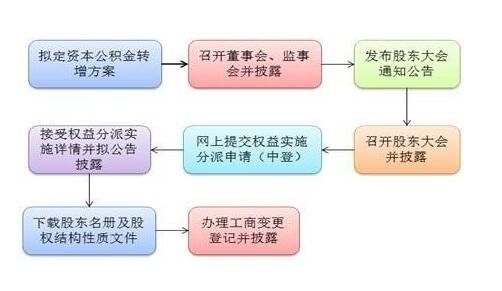









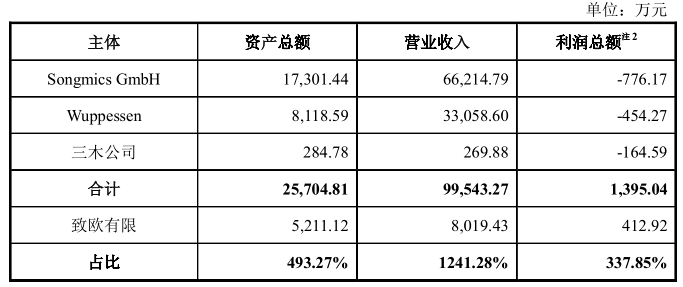




 营业执照公示信息
营业执照公示信息